Using AWS Lambda with S3
In this article, we're going to discuss on how to use AWS Lambda with S3 service for various use cases.
All code samples use typescript and use AWS CDK as Infrastructure as Code (IaC tool). If you're new to AWS CDK, I've written beginner's guide to AWS CDK here. Please read it. I can wait :-)
In this article, we're going to discuss about beginner and intermediate sections. In next article, we're going to discuss about advanced section - how to use AWS Lambda within private subnet of a VPC
Beginner
- Read S3 object contents
- Read S3 object contents based on a trigger
- Write a file to S3 object
- Write to local file system and upload to S3
Intermediate
- Trigger Lambda based on S3 object prefix and/or suffix
- Generate AWS S3 pre-signed url to upload files to S3
Advanced
- Run lambda inside VPC and access S3 using NAT Gateway
- Run lambda inside VPC and access S3 using Gateway Endpoint
- Run lambda inside VPC and access S3 using Interface Endpoint
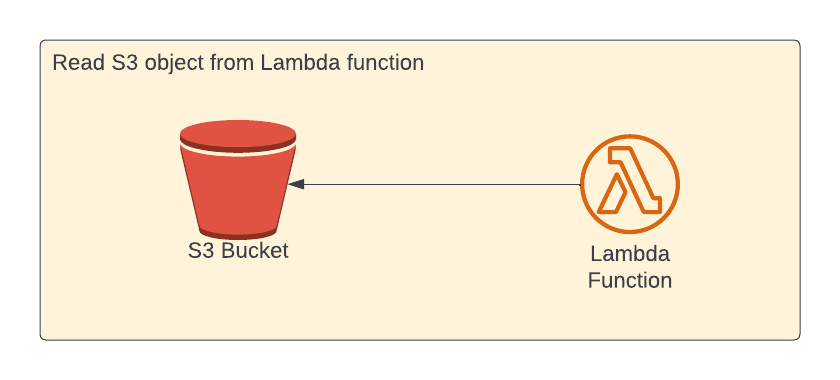
Read S3 object from AWS Lambda:
In this section, we're going to learn about how to read contents of a S3 object from Lambda function.
Bucket Creation
Create a new bucket as shown in below code snippet. As you know, S3 is a global service and the bucket name in S3 has to be unique. So, we're suffixing bucket id with unique identifier so that if many people (say readers of this blog) execute this code - AWS will not throw an error.
We want to delete all the objects of the bucket, if we destroy the stack in development environment. In production, we want to retain all the objects. We use the appropriate removal policy based on the environment variable.
const bucketId = ulid().toLowerCase();
const isProd = process.env.isProd ?? false;
const isDev = !isProd;
const removalPolicy = isDev ? RemovalPolicy.DESTROY : RemovalPolicy.RETAIN;
const bucket = new s3.Bucket(this, 'S3Bucket', {
bucketName: `aws-lambda-s3-${bucketId}`,
autoDeleteObjects: isDev,
removalPolicy,
});As we set the property autoDeleteObjects to true in this case, AWS CDK will create additional lambda automatically which will delete the objects of S3 bucket when we destroy the stack or when there is any change to the bucket name. You can see the created lambda in aws console.
Lambda function
Then, we create lambda function (with nodejs 16 runtime). We're passing bucket name as environment variable to the lambda function so that we can read it within lambda function. Please note that we need to give bucket read access to lambda function (as shown in the last line of below code snippet)
const nodeJsFunctionProps: NodejsFunctionProps = {
bundling: {
externalModules: [
'aws-sdk', // Use the 'aws-sdk' available in the Lambda runtime
],
},
runtime: Runtime.NODEJS_16_X,
timeout: Duration.minutes(3), // Default is 3 seconds
memorySize: 256,
};
const readS3ObjFn = new NodejsFunction(this, 'readS3Obj', {
entry: path.join(__dirname, '../src/lambdas', 'read-s3-obj.ts'),
...nodeJsFunctionProps,
functionName: 'readS3Obj',
environment: {
bucketName: bucket.bucketName,
},
});
bucket.grantRead(readS3ObjFn);Roles & Policies of Lambda
By default, lambda will have AWSLambdaBasicExecutionRole which has write permissions to CloudWatch. As we've granted read access to bucket, AWS CDK will generate a dynamic policies which has below permissions. You can see the same in AWS console in IAM service
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"s3:GetBucket*",
"s3:GetObject*",
"s3:List*"
],
"Resource": [
"arn:aws:s3:::aws-s3-lambda-random-id",
"arn:aws:s3:::aws-s3-lambda-random-id/*"
],
"Effect": "Allow"
}
]
}Lambda function code
Lambda function code is pretty simple. We're getting the bucket name from environment variable. We could have hard-coded the bucket name. As we're generating the bucket name dynamically, we're passing it as environment variable.
We want to read the contents of S3 object input-file.txt - we've mentioned the same as object key. Finally, we're reading contents of the file and printing the same in console (which we can see in CloudWatch).
import { S3Event } from 'aws-lambda';
import * as AWS from 'aws-sdk';
export const handler = async (
event: S3Event,
context: any = {}
): Promise<any> => {
const bucketName = process.env.bucketName || '';
const objectKey = 'input-file.txt';
const s3 = new AWS.S3();
const params = { Bucket: bucketName, Key: objectKey };
const response = await s3.getObject(params).promise();
const data = response.Body?.toString('utf-8') || '';
console.log('file contents:', data);
};
Once you deploy the stack using cdk deploy, all the AWS resources are created.
Testing
Login to AWS console and select AWS S3. You could see the bucket name starting with aws-lambda-s3 and my bucket name is aws-lambda-s3-01ger9xcsfxf8yfx9p7s5zw6mr and yours will be different.
Create a text file by name input-file.txt with some sample content. You can type anything you want in the text file. I've typed just hello world . Save the file and upload it to the bucket.
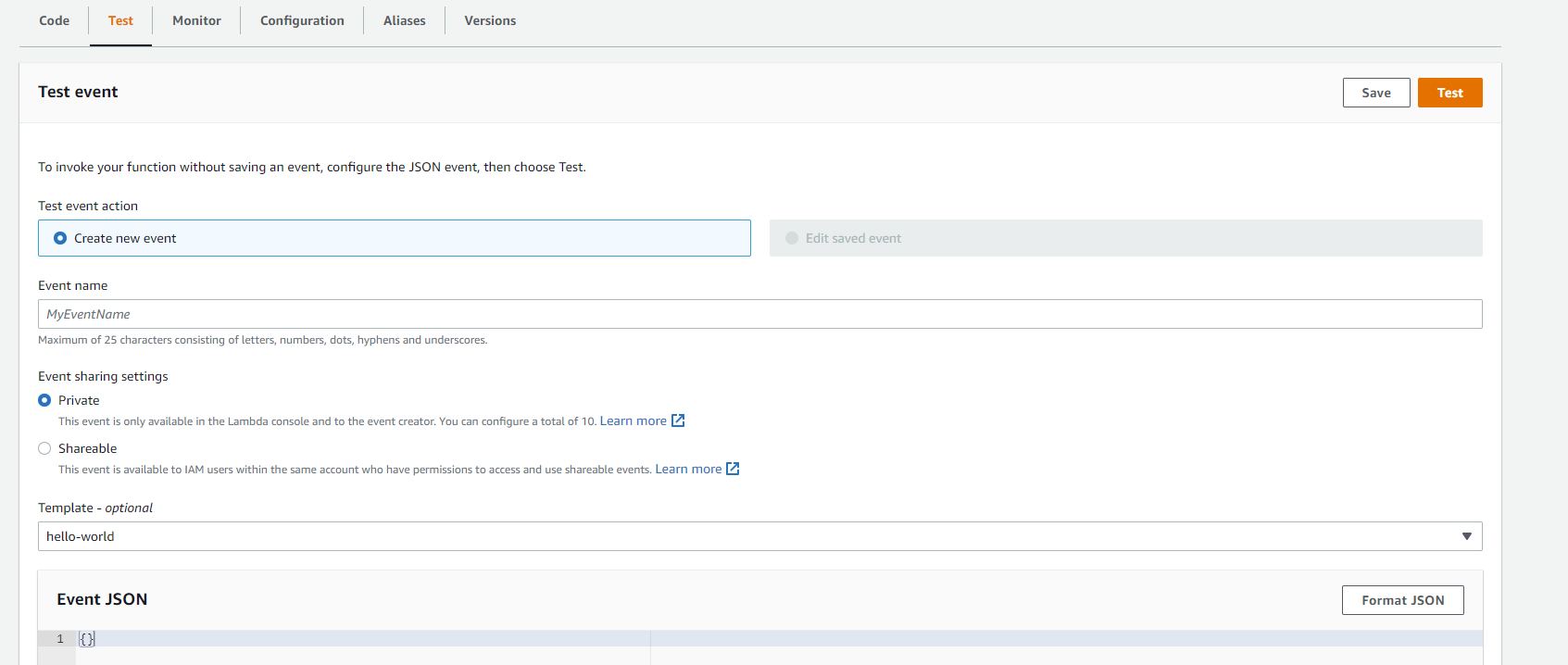
Then, select Lambda service in console and select Test tab and click Test function as shown in below screenshot. You can pass empty object as event as we're not using it our lambda function.
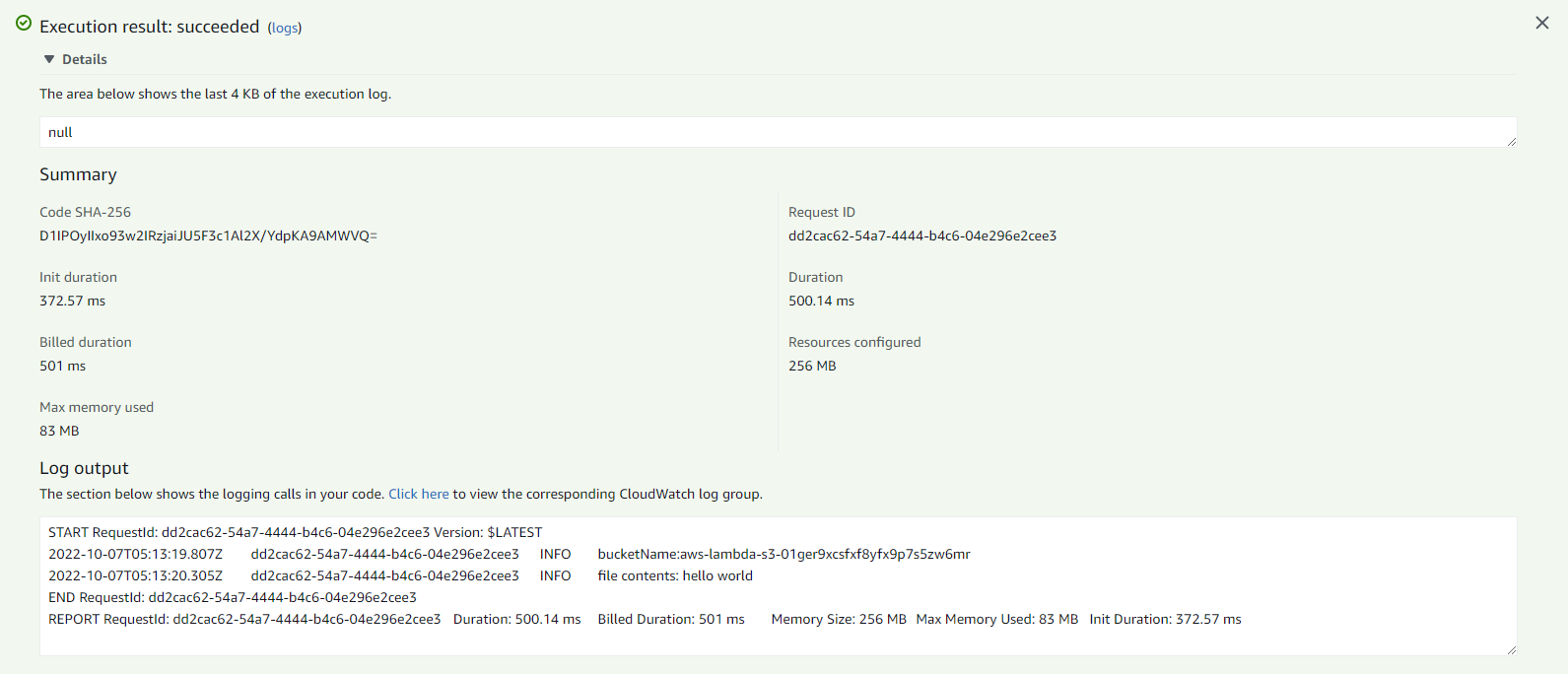
When you click Test button, lambda will get executed and you can see the ouput of lambda. You can even see the execution logs in CloudWatch too.
Read S3 object from AWS Lambda based on a trigger
In most of the cases, you would not want to execute lambda manually. Instead, we want the lambda to be executed automatically when we upload a file to S3 bucket.

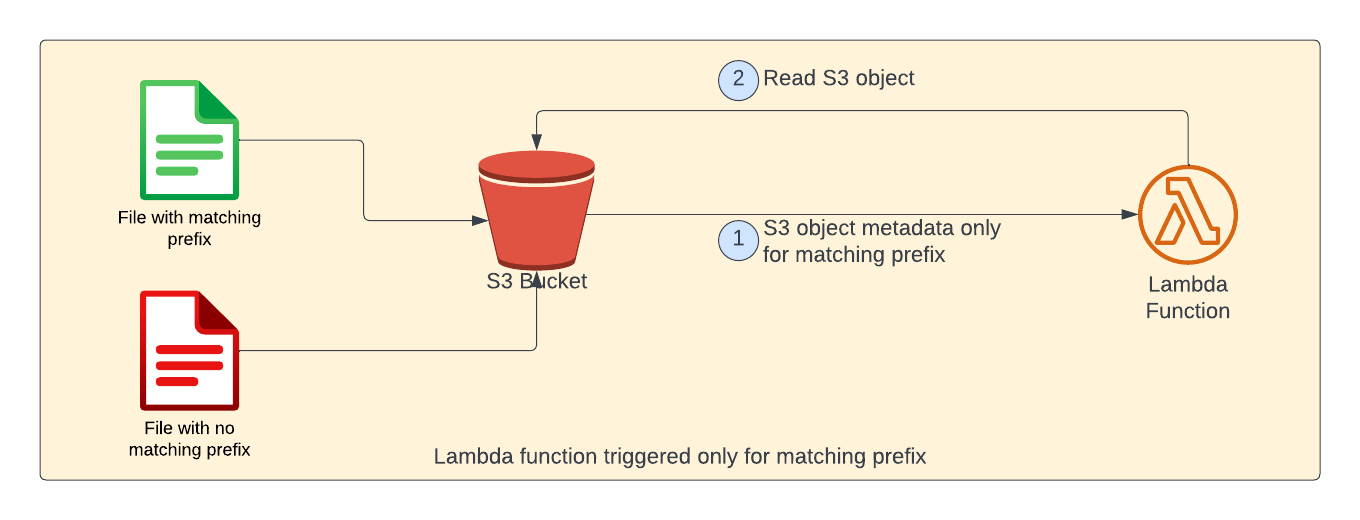
As shown in above picture, when an object is uploaded to S3 bucket, lambda will be called with S3 object metadata as event payload. Then, within lambda the contents of the S3 object is read and printed to the console.
Add event source for lambda function
We just need to add the event source to the lambda function. In below code snippet, we've added S3 event source with OBJECT_CREATED as trigger event for the lambda so that the lambda will be invoked when an object is created in this S3 bucket. Internally, AWS CDK will create additional lambda for handling this plumbing.
readS3ObjFn.addEventSource(
new S3EventSource(bucket, {
events: [s3.EventType.OBJECT_CREATED],
})
);There are many events available which you can use as event source for your lambda function. Below are some of most commonly used events
OBJECT_CREATED_PUTOBJECT_CREATED_POSTOBJECT_CREATED_COPYOBJECT_REMOVEDOBJECT_REMOVED_DELETE
Lambda function code
Lambda function code is updated as shown below. We'll get the bucket name from event payload.
export const handler = async (
event: S3Event,
context: any = {}
): Promise<any> => {
for (const record of event.Records) {
const bucketName = record?.s3?.bucket?.name || '';
const objectKey = record?.s3?.object?.key || '';
const s3 = new AWS.S3();
const params = { Bucket: bucketName, Key: objectKey };
const response = await s3.getObject(params).promise();
const data = response.Body?.toString('utf-8') || '';
console.log('file contents:', data);
}
};
Testing
You can delete the existing file input-file.txt and upload the same file again. Now, the lambda will be executed as soon as you upload the file. You can see the execution logs in CloudWatch service

Uploading multiple files at once
When multiple objects are uploaded, lambda will be invoked for each of these objects. For example, if you're uploading 3 files in the bucket, lambda will be invoked 3 times.
Write a file to S3 object using Lambda
In this section, we're going to write contents to a S3 object.
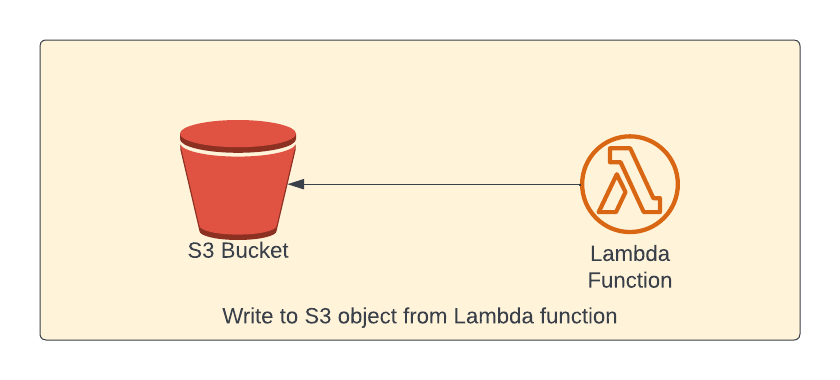
Lambda function permissions
Lambda function properties is similar to earlier lambda function. Only difference is the permission. We need to grant write permission to the bucket from lambda so that the lambda can write to S3 bucket (as shown in the last line of the below code snippet)
const writeS3ObjFn = new NodejsFunction(this, 'writeS3ObjFn', {
entry: path.join(__dirname, '../src/lambdas', 'write-s3-obj.ts'),
...nodeJsFunctionProps,
functionName: 'writeS3ObjFn',
environment: {
bucketName: bucket.bucketName,
},
});
bucket.grantWrite(writeS3ObjFn);Lambda function code
We just want to write some contents to a s3 object output-file.txt. Please note that this lambda creates s3 object with the contents.
import { S3Event } from 'aws-lambda';
import * as AWS from 'aws-sdk';
import { PutObjectRequest } from 'aws-sdk/clients/s3';
export const handler = async (
event: S3Event,
context: any = {}
): Promise<any> => {
const bucketName = process.env.bucketName || '';
const objectKey = 'output-file.txt';
const s3 = new AWS.S3();
const params: PutObjectRequest = {
Bucket: bucketName,
Key: objectKey,
Body: 'Contents from Lambda',
};
await s3.putObject(params).promise();
console.log('file is written successfully');
};
Once the file is written with content passed in Body parameter on putObject method, we're writing success message to the console which we can read it from CloudWatch later
Testing
Open AWS console and select lambda service. Select Test tab and click Test button by passing empty event object as we've done earlier.
The function will get executed and new S3 object output-file.txt will be created in the bucket.
Write to local file system and upload to S3
In this section, we're going to upload a file from local file system in lambda to S3 bucket. Lambda has read only access to the underlying file system except for /tmp directory. If you want to write anything - you'll be able to write ONLY to this /tmp directory.

There is no change to the lambda function properties and below is the lambda function source code. In below lambda function, we're writing text content to a file local file system in /tmp directory. Then, we're reading the file again and upload to S3.
import { S3Event } from 'aws-lambda';
import { promises as fsPromises } from 'fs';
import * as AWS from 'aws-sdk';
import { PutObjectRequest } from 'aws-sdk/clients/s3';
export const handler = async (
event: S3Event,
context: any = {}
): Promise<any> => {
const bucketName = process.env.bucketName || '';
const objectKey = 'output-file.txt';
const filePath = `/tmp/${objectKey}`;
await fsPromises.writeFile(filePath, 'Contents from Lambda to local file');
const fileContents = await fsPromises.readFile(filePath);
const s3 = new AWS.S3();
const params: PutObjectRequest = {
Bucket: bucketName,
Key: objectKey,
Body: fileContents,
};
await s3.upload(params).promise();
console.log('file is uploaded successfully');
};
Please note that we're using different method here - upload method of S3.
Testing
Once you deploy the changes using cdk deploy .You can execute the function manually from AWS console and you can see a new file created with the contents in lambda code.
Trigger AWS Lambda based on S3 object prefix and/or suffix
There are some cases where you want to trigger lambda on specified prefix and/or suffix of the S3 object key. For example, some other application in your system will write S3 objects with the key format as sales/{date-of-sale} .
For example, the name of the S3 object could be sales/10/12/2022 for the sales happened on 12th of October. You need to do some business logic by processing the sales information.
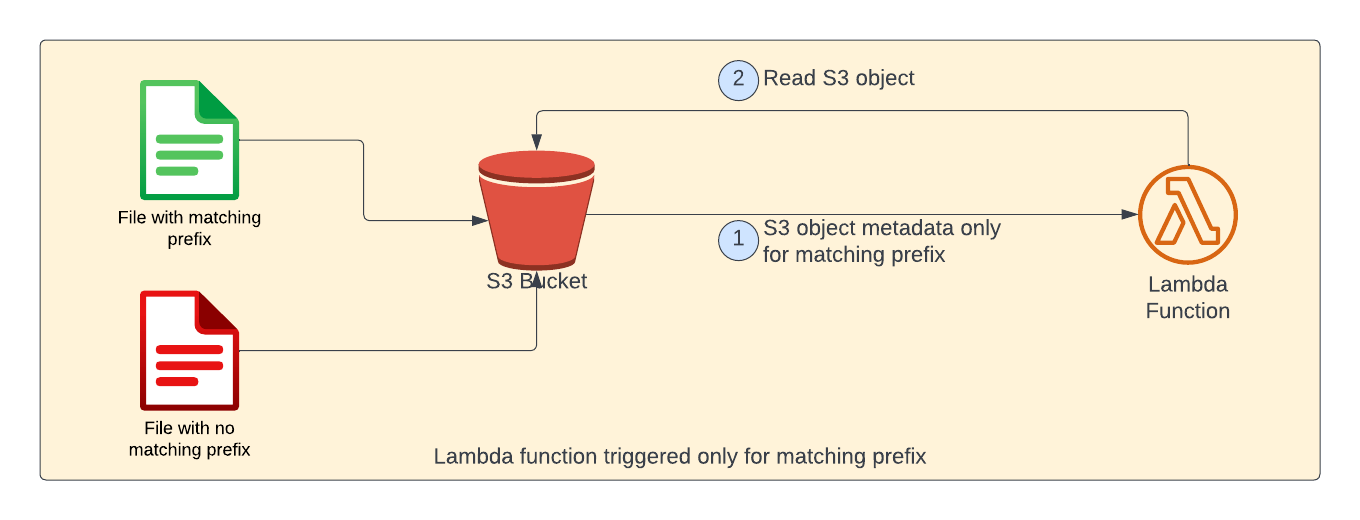
For example, when we try to upload 2 files - one with matching prefix (shown in green color) and other without matching prefix (shown in red color). S3 object notification would be sent only for the matching prefix. Please note that as far as lambda function is concerned, there is no change. S3 event notifications does all the filtering.
Lambda function Event Source
You can add filters to the S3 event notifications as shown below
readS3ObjPrefixFn.addEventSource(
new S3EventSource(bucket, {
events: [s3.EventType.OBJECT_CREATED],
filters: [{ prefix: 'sales/' }],
})
);readS3ObjPrefixFn is the reference to the lambda function. Earlier, we've used only events property. Now, we've used filters property to filter only the objects that have prefix sales/
As mentioned earlier, AWS CDK will create additional lambda for this notification.
Lambda function source code
There will be no change to the lambda source code. However, if you want to extract the date part from the object key, you can use below code snippet
import { S3Event } from 'aws-lambda';
import * as AWS from 'aws-sdk';
import { format, parse } from 'date-fns';
export const handler = async (
event: S3Event,
context: any = {}
): Promise<any> => {
for (const record of event.Records) {
const bucketName = record?.s3?.bucket?.name || '';
const objectKey = record?.s3?.object?.key || '';
//Take only the date part
const salesDateInStr = objectKey.replace(`sales/`, '').substring(0, 10);
//Parse the date so that it can be used later
const salesDate = parse(salesDateInStr, 'MM/dd/yyyy', new Date());
const s3 = new AWS.S3();
const params = { Bucket: bucketName, Key: objectKey };
const response = await s3.getObject(params).promise();
const data = response.Body?.toString('utf-8') || '';
console.log(`sales on ${salesDate.toISOString()} :`, data);
}
};
We've used prefix filter. You're free to use both prefix and suffix property in filters
Testing
When you try to upload, you'll not be able to able to upload the file with / character. So, you can use below aws cli command to upload normal file to S3 object with keys containing / . In below AWS CLI command, we want the file sales.txt to be uploaded as sales/10/12/2022/sales-data.txt S3 key in the bucket aws-lambda-s3-01gev17npa6m6yqfwy7rnfepda
aws s3 cp sales.txt s3://aws-lambda-s3-01gev17npa6m6yqfwy7rnfepda/sales/10/12/2022/sales-data.txtGet S3 pre-signed url from Lambda
Let us consider a scenario where you're building an API and you want to upload a large file at one of the endpoints. High level system design would look something like below.
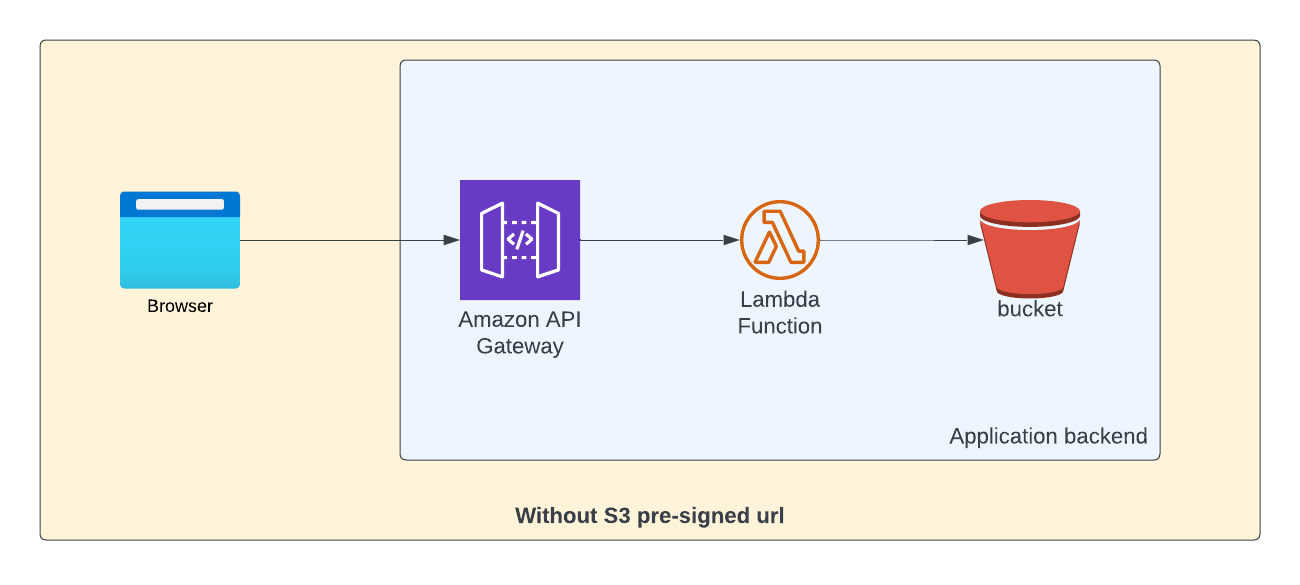
But there is a small problem with this approach. If you're trying to upload a file greater than 10 MB, it will fail as API Gateway has limit of 10 MB for its payload size.
The solution to this problem is to generate the pre-signed url for the s3 object using lambda and use that pre-signed url to upload file directly from client(browser in our case) by passing the entire application backend (Gateway and Lambda).
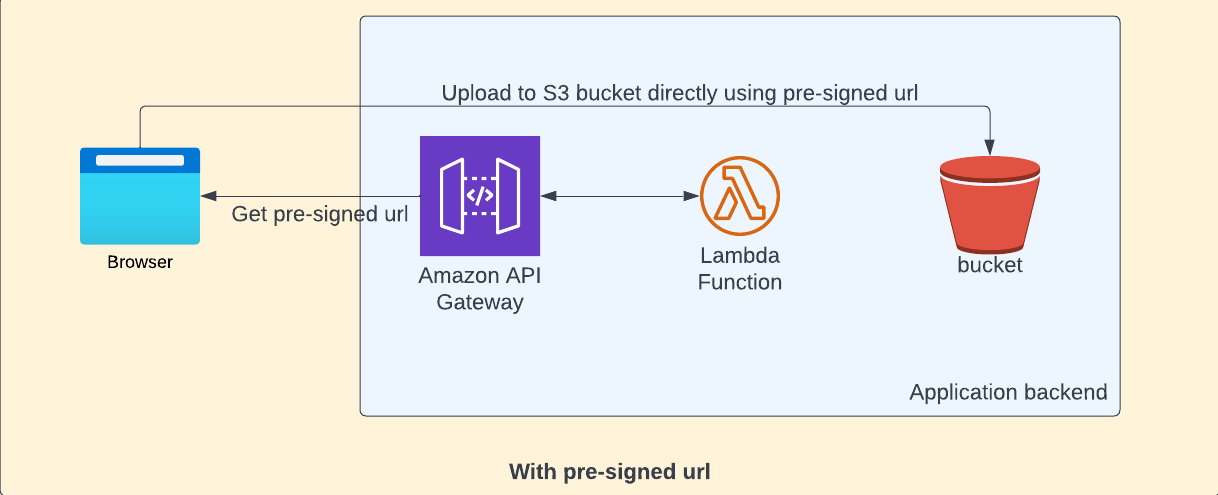
How it works
The call to generate the pre-signed url uses security token service to generate short term credentials and token. When you generate the pre-signed url itself, you need to specify the operation name - the generated url will be valid only for the specified operation( putObject in our case ). When we try to upload the file, it uses the generated security token. This token has expiry time after which the token will become invalid.
The generated URL has following query params
X-Amz-Algorithm- The hash algorithm that you used to create the request signature.X-Amz-Credential- The credential scope value, which is a string that includes your access key, the date, the region you are targeting, the service you are requesting, and a termination string ("aws4_request"). The value is expressed in the following format: access_key/YYYYMMDD/region/service/aws4_request.X-Amz-Date- The date that is used to create the signature.X-Amz-Expires- Time to expire ( in seconds)X-Amz-Security-Token- The temporary security token that was obtained through a call to AWS Security Token Service (AWS STS).X-Amz-Signature- Specifies the hex-encoded signature that was calculated from the string to sign and the derived signing key.X-Amz-SignedHeaders- Specifies all the HTTP headers that were included as part of the canonical request
Infrastructure code
The infrastructure code will be similar to existing code. And, please remember to grant bucket write access to lambda function
const bucket = new s3.Bucket(this, 'S3Bucket', {
bucketName: `aws-s3-lambda-presigned-url`,
autoDeleteObjects: isDev,
removalPolicy,
});
const nodeJsFunctionProps: NodejsFunctionProps = {
bundling: {
externalModules: [
'aws-sdk', // Use the 'aws-sdk' available in the Lambda runtime
],
},
runtime: Runtime.NODEJS_16_X,
timeout: Duration.minutes(3), // Default is 3 seconds
memorySize: 256,
};
const presignedUrlFn = new NodejsFunction(this, 'preSignedUrlFn', {
entry: path.join(__dirname, '../src/lambdas', 'pre-signed-url.ts'),
...nodeJsFunctionProps,
functionName: 'preSignedUrlFn',
});
bucket.grantWrite(presignedUrlFn);Lambda function code
We just need to call the getSignedUrlPromise method by passing bucket and object key parameters
import { S3Event } from 'aws-lambda';
import * as AWS from 'aws-sdk';
export const handler = async (
event: S3Event,
context: any = {}
): Promise<any> => {
const bucketName = 'aws-s3-lambda-presigned-url';
const objectKey = 'large-file.jpeg';
const s3 = new AWS.S3({
signatureVersion: 'v4',
});
const preSignedUrl = await s3.getSignedUrlPromise('putObject', {
Bucket: bucketName,
Key: objectKey,
});
console.log('preSignedUrl:', preSignedUrl);
};
Testing
When you execute lambda, we'll be getting the pre-signed url. We can do PUT request to the pre-signed url that we got from lambda.
You can execute lambda manually from AWS console itself to get the pre-signed url. In the Body tab of below window, you can select binary content and upload the file large-file.jpeg
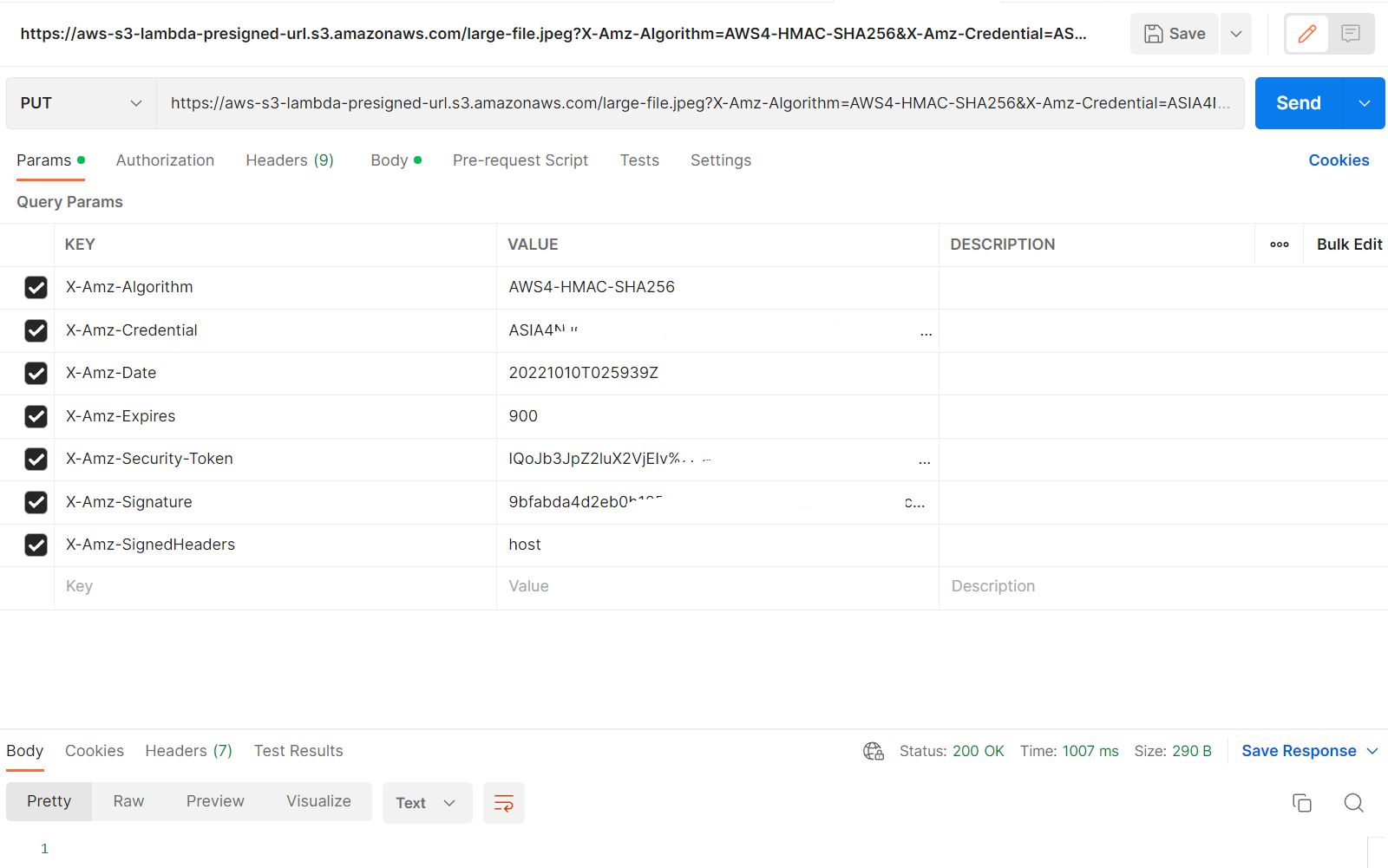
Once the request is successful, you can check the uploaded file in S3.
Please let me know your thoughts in comments