How to run Playwright with Python in AWS Lambda

In this article, we will learn how to run Playwright with Python in AWS Lambda. For those who don't know what Playwright is - Playwright is the framework for web testing and automation. It allows testing Chromium, Firefox, and WebKit with a single API.
Option 1: Use the base image provided by AWS Lambda and install all the necessary dependencies(both browser and system dependencies)
Option 2:Create a standard docker image used for Playwright and implement the runtime interface client for AWS Lambda
Out of the above 2 options, option 2 is easier to implement because of the following reason
Python docker image provided by lambda is based on Amazon Linux whereas the Playwright library depends on some of the libraries provided by Ubunutu
Why do we use Playwright with AWS Lambda?
If you use AWS Lambda, you'll be billed only for the time your function is executed. And, AWS Lambda has great integration with other AWS services such as DynamoDB, SQS, and others. So, if your solution is hosted in AWS - AWS Lambda is a great option to consider.
What problem do we face when using Playwright with AWS Lambda?
Let's create a simple AWS CDK project. I would install the Playwright package and add the below lambda function
from playwright.sync_api import sync_playwright
def handler(event, context):
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
page.goto("http://whatsmyuseragent.org/")
print("finished")
browser.close()
I deploy the stack using cdk deploy command. When I try to run the lambda function from the console, I get the below error
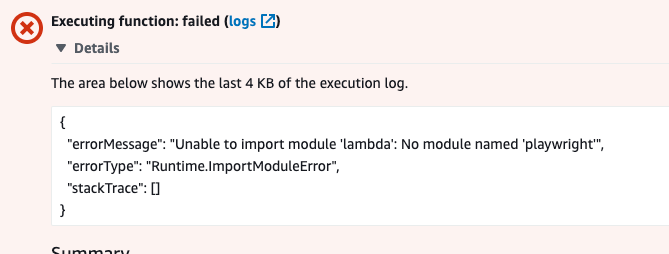
The error message says that lambda is unable to import playwright. But we've added this package in requirements.txt and installed it. So, what's the problem?
In order to resolve this problem, we need to understand how playwright works.
How does Playwright work?
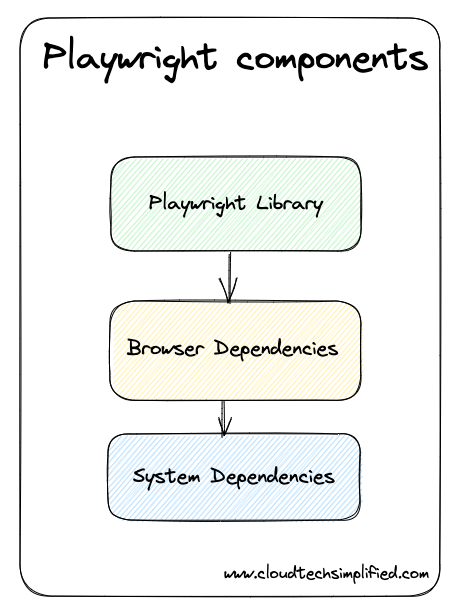
In order for to playwright to work properly - we need to have 3 components to work together
- Playwright library - This is the actual library that contains the functionality of API for automating browsers, interacting with web pages
- Browser Dependencies - Playwright depends on the specific browser. For example, we can use chromium for chrome browser, webkit for safari, and Firefox for firefox browser
- System dependencies: These are system dependencies that need to be installed. These dependencies include various libraries and packages that are necessary for Playwright to function correctly and communicate with the underlying operating system
The reason why we were getting errors earlier is that we've just installed - the playwright library and we didn't have other components( browser dependencies and system dependencies)
How to run Playwright in AWS Lambda
As mentioned in this article, even though we can any docker container using AWS Lambda, it needs to implement the runtime interface client to manage the interaction between lambda and function code.
So, there are 2 options for running the playwright in AWS Lambda
- Option 1: Use the below base image provided by AWS Lambda and install all the necessary dependencies(both browser and system dependencies)
public.ecr.aws/lambda/python:3.8- Option 2: Create a standard docker image used for Playwright and implement the runtime interface client for AWS Lambda
Out of the above 2 options, option 2 is easier to implement because of the following reason
- Python docker image provided by lambda is based on Amazon Linux whereas the Playwright library depends on some of the libraries provided by Ubunutu
Docker image for Playwright Python in AWS Lambda
We're going to use the base image mcr.microsoft.com/playwright/python:v1.21.0-focal provided by Microsoft for running the playwright in Python.
We need to do the following things for creating docker image
- Use the base image
mcr.microsoft.com/playwright/python:v1.21.0-focalprovided by Microsoft. This base image contains playwright library with browser & system dependencies - Update the dependencies by using the below command
RUN apt-get update && \
apt-get install -y \
g++ \
make \
cmake \
unzip \
libcurl4-openssl-dev- Create a function directory and copy your lambda function code to the function directory
# Create function directory
RUN mkdir -p ${FUNCTION_DIR}
# Copy function code
COPY app/* ${FUNCTION_DIR}- Install the runtime interface client of AWS Lambda
# Install the runtime interface client
RUN pip3 install \
--target ${FUNCTION_DIR} \
awslambdaric- Set the entry point and command to run
ENTRYPOINT [ "/usr/bin/python", "-m", "awslambdaric" ]
CMD [ "app.handler" ]Below is the complete Dockerfile for creating the image.
# Define function directory
ARG FUNCTION_DIR="/function"
FROM mcr.microsoft.com/playwright/python:v1.21.0-focal as build-image
# Install aws-lambda-cpp build dependencies
RUN apt-get update && \
apt-get install -y \
g++ \
make \
cmake \
unzip \
libcurl4-openssl-dev
# Include global arg in this stage of the build
ARG FUNCTION_DIR
# Create function directory
RUN mkdir -p ${FUNCTION_DIR}
# Copy function code
COPY app/* ${FUNCTION_DIR}
# Install the runtime interface client
RUN pip3 install \
--target ${FUNCTION_DIR} \
awslambdaric
# Multi-stage build: grab a fresh copy of the base image
FROM mcr.microsoft.com/playwright/python:v1.21.0-focal
# Include global arg in this stage of the build
ARG FUNCTION_DIR
# Set working directory to function root directory
WORKDIR ${FUNCTION_DIR}
# Copy in the build image dependencies
COPY --from=build-image ${FUNCTION_DIR} ${FUNCTION_DIR}
ENTRYPOINT [ "/usr/bin/python", "-m", "awslambdaric" ]
CMD [ "app.handler" ]
The app directory contains the simple file app.py with following contents
from playwright.sync_api import sync_playwright
def handler(event, context):
with sync_playwright() as p:
browser = p.chromium.launch(args=["--disable-gpu", "--single-process"])
page = browser.new_page()
page.goto("http://whatsmyuseragent.org/")
print("finished")
browser.close()
You can build and push the image to AWS ECR. In this example, I'm going to push the code to the ECR repo playwright-python-repo from CLI - just for the sake of simplicity. You can get the commands by clicking "View Push Commands" button at ECR.
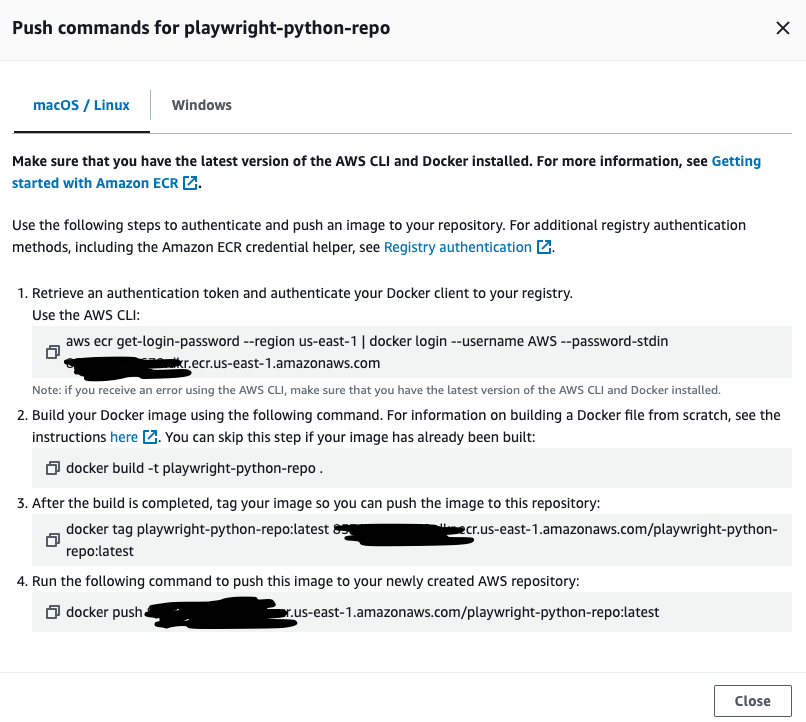
Of course, we can build a CI/CD pipeline as explained in this article.
Consuming the image in AWS Lambda
I'm going to create a simple AWS CDK stack in Python to create a lambda function. If you're new to AWS CDK, I've written detailed step-by-step guide on AWS CDK here. I've explained the benefits and how to start on AWS CDK in that article.
class PlaywrightStack(Stack):
def __init__(self, scope: Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
repo = ecr.Repository.from_repository_name(
self, "Repo", "playwright-python-repo"
)
lambda_fn = _lambda.DockerImageFunction(
self,
"playwright-python-lambda",
code=_lambda.DockerImageCode.from_ecr(repo),
function_name="playwright-python-lambda",
memory_size=512,
timeout=Duration.seconds(600),
)
You can deploy the above stack using cdk deploy command. It would create the lambda function.
Using Console:
If you're just prototyping or testing, you can use "Container image" as shown below
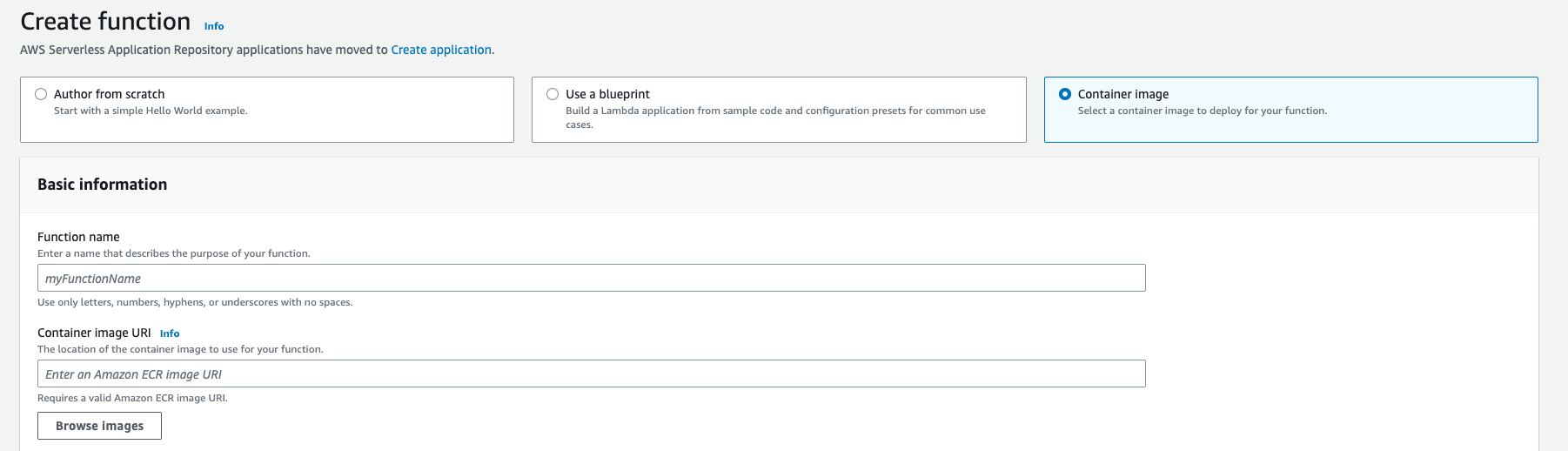
You can enter the function name and click "Browse Images" to select the image.
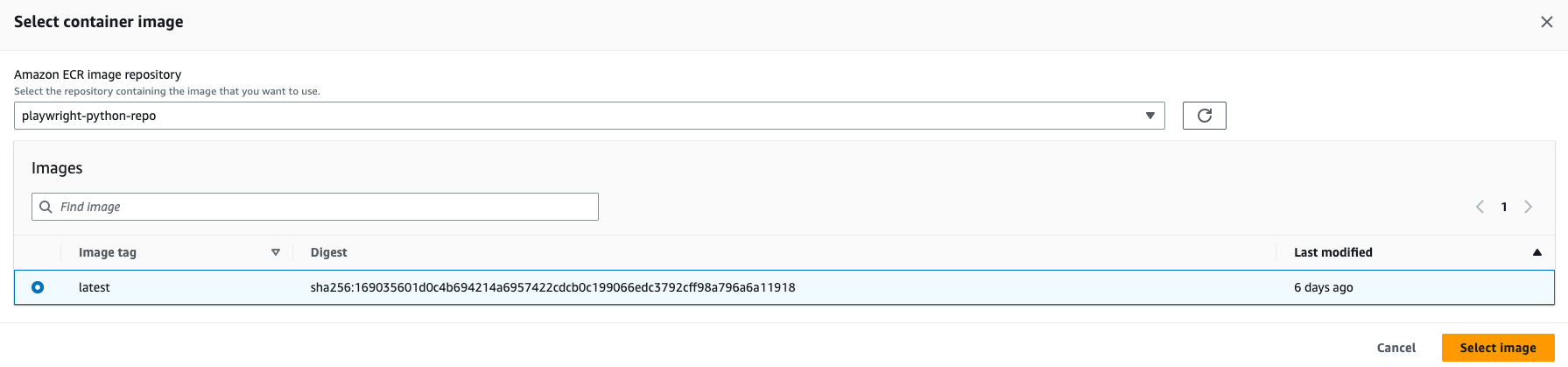
Running the lambda function:
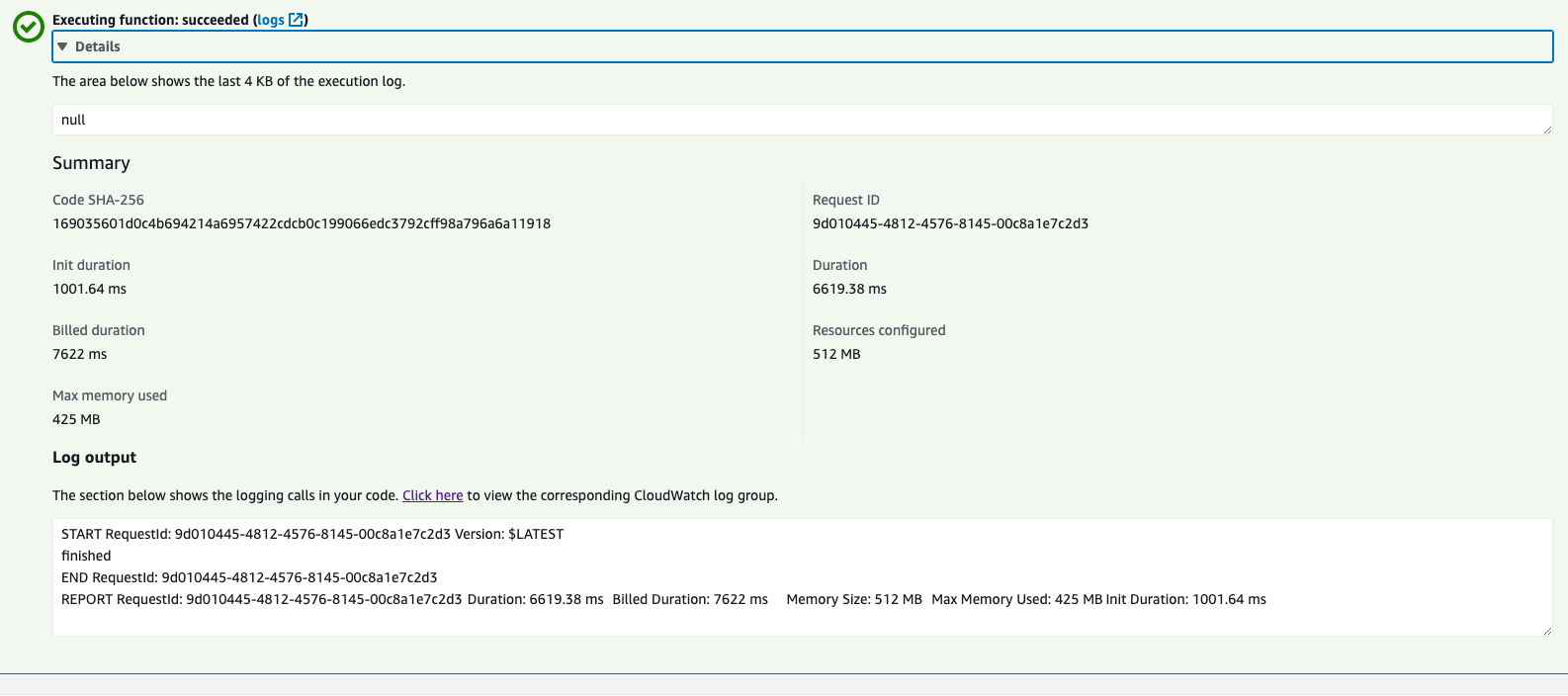
You can log in to AWS Console and run the lambda function manually and you would be able to see the below output. Of course, you can have this lambda function behind an API Gateway and expose this lambda function as Lambda integration for one of your API endpoints.
Please let me know your thoughts in the comments