Using Environment variables and secrets (API keys, database passwords) in AWS Lambda

In this article, you're going to learn how to use environment variables and pass sensitive information such as API keys and database passwords securely to AWS Lambda using TypeScript.
The Python version of this article is available here
What are Environment Variables?
Environment variables are variables whose values are set outside of the program (in our case - this program is lambda function) and are usually a key-value pairs. It is important to note that the program is never changed across environments and the values of these environment variables are fetched within the program.
For example, if you're running a program in local environment - you might want to refer to the database installed on your local machine. If you're running the same program in dev environment - you would want to refer to the dev database.
Kinds of environment variables used in lambda
At high level, you can categorize the data that you might want to pass as environment variables to your lambda function into 2 kinds
- Non-Sensitive data such as bucket name, dynamodb table name, etc..
- Sensitive data such as API keys, username and password of the database etc..
Apart from this, AWS Lambda itself has some default environment variables.
Non-sensitive data
Let's consider a scenario where you have a dynamodb table for storing the sales transactions. At the end of day, you might want to run some lambda function to process the sales information for that day.
In this case, your lambda function needs to know the name of the dynamodb table. You can pass this as environment variable directly as this information is not sensitive.
In below code snippet (which usesaws-cdk ) , we're creating the dynamodb table with a single partition key.
const table = new ddb.Table(this, 'salesTable', {
tableName: 'Sales',
partitionKey: {
name: 'id',
type: ddb.AttributeType.STRING,
},
billingMode: BillingMode.PAY_PER_REQUEST,
});Then, we create lambda function which uses Node16 as runtime. We configure timeout and memory size for the lambda function.
const nodeJsFunctionProps: NodejsFunctionProps = {
bundling: {
externalModules: [
'aws-sdk', // Use the 'aws-sdk' available in the Lambda runtime
],
},
runtime: Runtime.NODEJS_16_X,
timeout: Duration.minutes(3), // Default is 3 seconds
memorySize: 256,
};We pass the tableName as environment variable to the lambda function.
const readDDBLambdaFn = new NodejsFunction(this, 'readDDBLambdaFn', {
entry: path.join(__dirname, '../src/lambdas', 'read-ddb.ts'),
...nodeJsFunctionProps,
functionName: 'readDDBLambdaFn',
environment: {
tableName: table.tableName,
},
});When you deploy using cdk deploy, CDK would create all AWS resources.
You can see the environment variables (along with the values in plain text) created earlier are shown in Environment Variables section of Configuration tab.
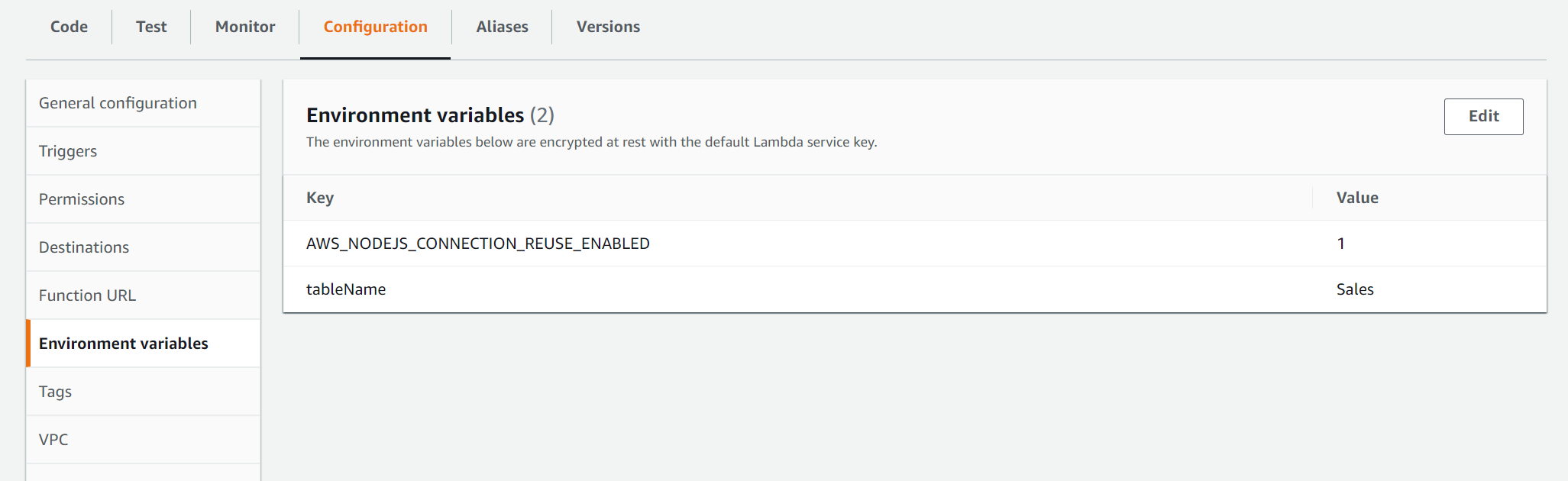
As this is not a sensitive data, you can pass the dynamodb table information as environment variable.
AWS_NODEJS_CONNECTION_REUSE_ENABLED is the default environment variables that lambda uses for re-using connections. We'll discuss about these default variables later in this article.
How to use the environment variables in Lambda function
There is no difference between accessing environment variables from lambda function to any other program.
If you're using typescript or JavaScript, you can use process.env.variableName
Below is the actual lambda function code for retrieving the environment variable
export const handler = async (
event: any = {},
context: any = {}
): Promise<any> => {
const tableName = process.env.tableName || '';
// query the table
};
Permissions
It is obvious but worth to re-iterate that even though you can get the dynamodb table name from environment variable, you need to have necessary permissions to access the table
You can give the permissions like this in cdk for read access.
table.grantReadData(readDDBLambdaFn);Sensitive data
Let's consider a scenario where you've a database and want your lambda function to interact with the RDS database.
In this case, your lambda function should have access to host name, user name and password for the database to communicate with the RDS database or aurora or any other form of database.
As user name and password of the database are sensitive information - it is not advisable to pass this information directly as environment variables to your lambda function. As shown earlier, all environment variables that you pass into the lambda function would be visible in AWS console.
This is the reason why you should never pass sensitive data as environment variables directly to your lambda function.
For sensitive information, you need to store the sensitive information in parameter store or secrets manager and then pass name or ARN(Amazon Resource Name) as environment variable to your lambda function.
Lambda function can fetch the sensitive information from the parameter store or secrets manager dynamically within lambda function and then use that information in the lambda function
Passing sensitive information using parameter store
Let us assume that our lambda talks to an external API and this API requires a API Key. As this is a sensitive information, you can't pass this information as plain text. So, we've stored value of API key by name ( API_KEY )in parameter store. We're referring to the parameter from parameter store using below cdk code
const apiKey = 'API_KEY';
const ssmParam = ssm.StringParameter.fromSecureStringParameterAttributes(
this,
'ssmParameter',
{
parameterName: apiKey,
}
);Then, we're creating lambda function with Node16 as runtime and configuring timout and memory size properties.
const nodeJsFunctionProps: NodejsFunctionProps = {
bundling: {
externalModules: [
'aws-sdk', // Use the 'aws-sdk' available in the Lambda runtime
'pg-native',
],
},
runtime: Runtime.NODEJS_16_X,
timeout: Duration.minutes(3), // Default is 3 seconds
memorySize: 256,
};Passing name of Parameter ( of senstive data) to Lambda function
We're passing the key name ( API_KEY )as environment variable. Please note that we're NOT passing the actual secret value. It is just a key.
const apiLambdaFn = new NodejsFunction(this, 'apiLambdaFn', {
entry: path.join(__dirname, '../src/lambdas', 'api-lambda.ts'),
...nodeJsFunctionProps,
functionName: 'apiLambdaFn',
environment: {
API_KEY: apiKey,
},
});
Permissions for lambda to read the secret
Our lambda will talk to parameter store to get the actual secret value but it needs to permission to retrieve that value. Below line of code would grant that permission.
ssmParam.grantRead(apiLambdaFn);Lambda function code
Our lambda function talks to parameter store to retrieve the secret value - and then it can use that value to communicate with external API.
import * as AWS from 'aws-sdk';
export const handler = async (event: any, context: any): Promise<any> => {
const ssm = new AWS.SSM();
const apiKey = process.env.API_KEY || '';
const params: AWS.SSM.GetParameterRequest = {
Name: apiKey,
WithDecryption: true,
};
const apiKeyResult: AWS.SSM.GetParameterResult = await ssm
.getParameter(params)
.promise();
const apiKeyValue = apiKeyResult.Parameter?.Value;
// use the api key value
};
Creating database with credentials as secret stored in Secrets Manager
You can also use Secrets Manager to store and retrieve secrets required for your lambda. Secrets Manager has additional functionalities such as secret rotation.
In below cdk code, we're creating database instance in existing VPC.
const databaseName = 'ecommerce';
const dbInstance = new rds.DatabaseInstance(this, 'Instance', {
engine: rds.DatabaseInstanceEngine.postgres({
version: rds.PostgresEngineVersion.VER_13,
}),
// optional, defaults to m5.large
instanceType: ec2.InstanceType.of(
ec2.InstanceClass.BURSTABLE3,
ec2.InstanceSize.SMALL
),
vpc,
vpcSubnets: vpc.selectSubnets({
subnetType: ec2.SubnetType.PRIVATE_WITH_EGRESS,
}),
databaseName,
credentials: rds.Credentials.fromGeneratedSecret('postgres'),
maxAllocatedStorage: 200,
});Creation of secret
Please note that rds.Credentials.fromGeneratedSecret('postgres') will create a secret in secrets manager with the passed value as user name. As we're talking to postgres database, we've specified user name as postgres
Passing the secret arn as environment variable to Lambda
You can pass the database endpoint and database name as environment variables directly. However, for database password, you can pass the secret arn to the lambda function.
const rdsLambdaFn = new NodejsFunction(this, 'rdsLambdaFn', {
entry: path.join(__dirname, '../src/lambdas', 'rds-lambda.ts'),
...nodeJsFunctionProps,
functionName: 'rdsLambdaFn',
environment: {
DB_ENDPOINT_ADDRESS: dbInstance.dbInstanceEndpointAddress,
DB_NAME: databaseName,
DB_SECRET_ARN: dbInstance.secret?.secretFullArn || '',
},
vpc,
vpcSubnets: vpc.selectSubnets({
subnetType: ec2.SubnetType.PRIVATE_WITH_EGRESS,
}),
});Fetching the actual secret from lambda
In Lambda, you can fetch the actual password value from secrets manager and use this information to communicate with the database.
We're using getSecretValue method of Secrets Manager to fetch the actual secret. Please note that it will be a JSON string(in this case) with username and password properties.
import * as AWS from 'aws-sdk';
import { Client } from 'pg';
export const handler = async (event: any, context: any): Promise<any> => {
const host = process.env.DB_ENDPOINT_ADDRESS || '';
const database = process.env.DB_NAME || '';
const dbSecretArn = process.env.DB_SECRET_ARN || '';
const secretManager = new AWS.SecretsManager({
region: 'us-east-1',
});
const secretParams: AWS.SecretsManager.GetSecretValueRequest = {
SecretId: dbSecretArn,
};
const dbSecret = await secretManager.getSecretValue(secretParams).promise();
const secretString = dbSecret.SecretString || '';
if (!secretString) {
throw new Error('Password is empty');
}
const { password } = JSON.parse(secretString);
const client = new Client({
user: 'postgres',
host,
database,
password,
port: 5432,
});
await client.connect();
};
Default environment variables
Till now, we've discussed about the environment variables that we've passed explicitly. However, Lambda service has several environment variables that it uses and some the environment variables are set to sensible defaults which you can override them.
LAMBDA_TASK_ROOT is the environment variable which contains the path of your lambda code
AWS_LAMBDA_FUNCTION_VERSION is the environment variable which tells us the version of the lambda function
By default, your NodeJS lambda function will create a new TCP connection for every request. As you might know that it may take sometime to create a new TCP connection.
If you set the environment variable AWS_NODEJS_CONNECTION_REUSE_ENABLED
Conclusion
Hope you've learnt a bit about passing environment variables in AWS Lambda.
Please let me know your thoughts in comments.